# my global config global: scrape_interval:15s# Set the scrape interval to every 15 seconds. Default is every 1 minute. evaluation_interval:15s# Evaluate rules every 15 seconds. The default is every 1 minute. # scrape_timeout is set to the global default (10s).
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'. rule_files: # - "first_rules.yml" # - "second_rules.yml"
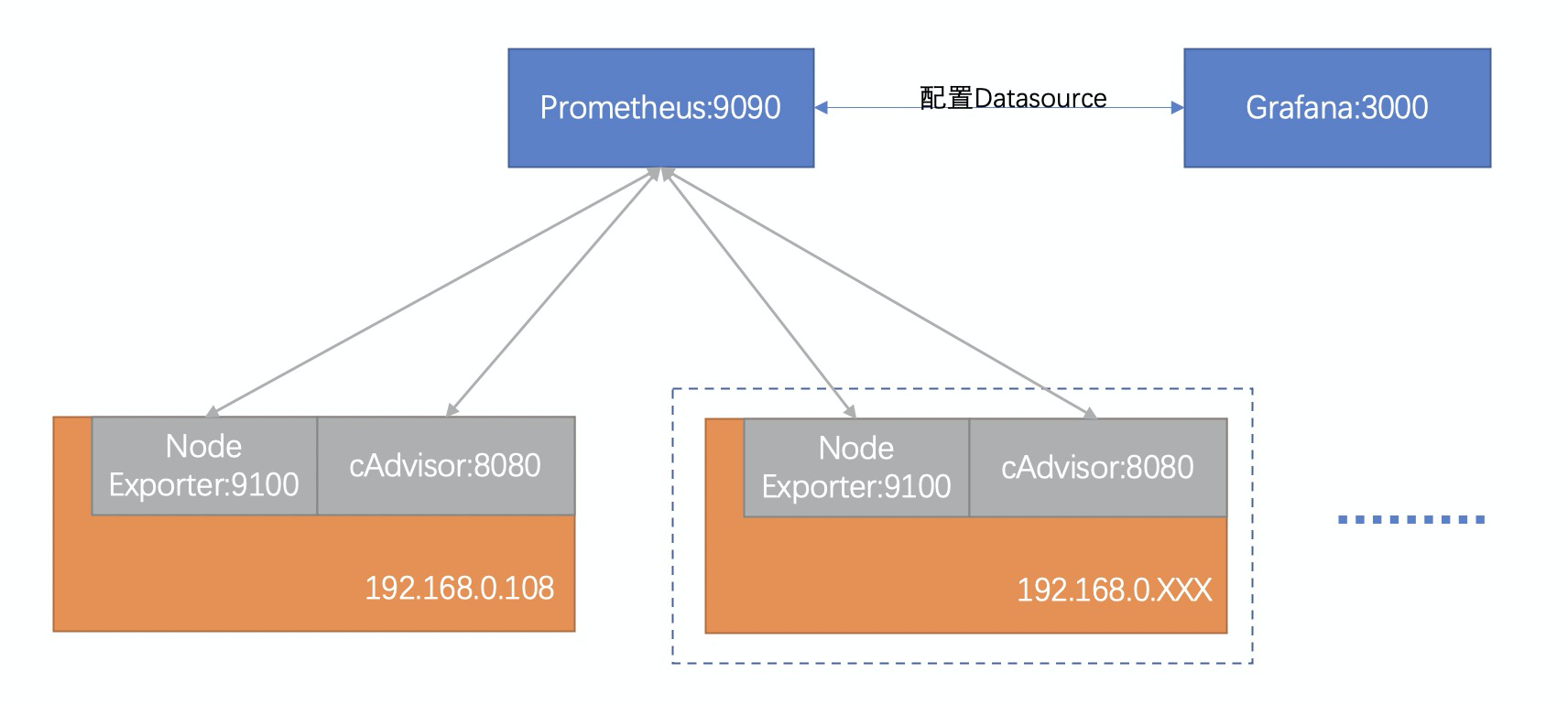
# A scrape configuration containing exactly one endpoint to scrape: # Here it's Prometheus itself. scrape_configs: # The job name is added as a label `job=<job_name>` to any timeseries scraped from this config. -job_name:"prometheus" # metrics_path defaults to '/metrics' # scheme defaults to 'http'. static_configs: -targets: ["localhost:9090"] -job_name:"docker-cluster" static_configs: -targets: ["192.168.0.108:9100","192.168.0.108:8080"]